
The importance of metadata in an analytics system cannot be overstated. It gives context to the details of customer behavior and quality measurements, and it makes it possible to create relevant aggregates in the system, to understand the measurement data in different contexts.
One of the important metadata categories in the system is the asset name-related metadata for the consumed video assets. This data includes the live/VoD specification, channel name, VoD asset name, and service name to which the asset belongs to.
For example, live/CNN/free channels, or VoD/Citizen Kane/nPVR.
Having correct asset-related metadata makes it possible to understand service and content popularity per provider, as well as the quality of experience per service or channel, and therefore identify troublesome VoD-assets.
Make sure the metadata is correct
Agama integration certification process usually assures that the correct metadata is provided by the integration, but there are several reasons a system may be populated with incorrect information.
An old end-of-life device with a partial integration can’t be updated on backend change, or correct information is not available to the application when making the integration – to mention a few. For this reason, the Agama system provides an advanced mechanism for making the most out of the available metadata from the device integration and from external sources.
Asset name washing
The basic principle for the washing mechanism is the following:
- Use URI to categorize a session
- Optionally pass-through sessions that have the metadata specified, if information from the device is the preferred source of information
- Extract asset name and service name specification from URI
- Optionally override live/VoD flag
- Map channel names to URIs from external inventory sources such as channel name inventory
The picture below illustrates the steps that the system takes when metadata washing is configured.
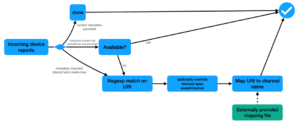
Hands-on configuration
To get an understanding of how configuration is done, here’s an example. The yaml file snippets are a part of the data-transformation.yaml file, which is a part of the RTN-service configuration and must be identical on all nodes.
In this system, we conclude that integrations report incorrect asset-names and live/VoD-specification. Therefore, we chose to discard the information set by the devices and create new metadata based on the session URI.
First, we specify that we want to create new metadata disregarding the integration.
prefer-asset-id-from-uri: true
After this, we proceed to specify the rules for creating the needed metadata.
The rules
The first rule in priority order aims to match all live sessions and override asset-name and live/VoD metadata coming from the client.

- higher priority is executed first, while the enabled flag enables the rule
- match part of the rule matches on session URI to decide if the rule should be applied
- asset part extracts a part of the URI for later mapping with the external file as this rule is for live channels
- the type part, if present, overrides live/VoD specification that comes from the client
- the server section extracts server name/ip for server-based aggregates
The next rule in priority order aims to match all VOD sessions and based on the URI call them PLTV-<assetid> or TVOD-<assetid>.

- most of the specification works in exactly the same way as in the previous rule
- asset replace specification is new. It extracts groups from the URI and creates an asset name based on the substrings in the URI
The final rule, executed at the end, aims to catch any unexpected URIs that didn’t match any previous rule. We don’t expect to end up here, but it is good protection for not accidentally creating tens of thousands of aggregates by mistake.

Mapping the file
After applying regex rules, the system will optionally try to map results from regex output with a list of mappings provided in a csv-file.
Configuration for enabling this feature:

This configuration allows you to specify the mapping file, presence of a header in file and column names to use for matching as well as the result column. Being able to specify columns allows you to use csv files that have more columns than the required ones and sometimes spares the administrator the work of modifying a file that is already available from an internal inventory.
To sum up
In conclusion, there are several topics to be considered in order to clean up the asset-related metadata and get consistent and correct information in the system:
- Have correct channel names available in the system
- Maintain correct playlist type specification
- Users can differentiate between PLTV and TVOD assets in the system
- Backend changes will not risk creating excessive amounts of data in the system thanks to a “catch all”-rule.
This is all that is needed to have consistent aggregates in your system and easily identify problematic VoD assets.

About Aner Gusic
Aner is a Senior Engineer and Product Expert, focusing on customer success, as well as on product development projects, in order to deliver professional solutions for video analytics and monitoring. Aner has more than 15 years of experience in IT and telecom industry, working in both technical and leadership positions.